
 par
par Suite de l’article précédent Monitorer son infra avec Warp 10 – partie 1.
Nous avons vu comment installer sensision et remonter des métriques dans Warp 10. Maintenant, explorons ces métriques.
Pour avoir la liste complète des métriques, vous pouvez requêter votre instance Warp 10 avec WarpStudio en y ajoutant les infos de connexion.
Retrouvez plus d’info sur WarpStudio ici : https://blog.senx.io/warpstudio-unleashed/
Puis exécutez ce WarpScript :
[
'votre token de lecture'
'~.*' {}
] FINDRetrouvez la documentation de FIND.
Je vous encourage donc à tester différents scripts (référez vous à la donc Warp 10) pour explorer un peu ces données.
Par exemple, récupérons 24 heures de données sur le trafic réseau en réception :
[
'votre token de lecture'
'linux.proc.net.dev.receive.bytes'
{ 'hname' 'votre serveur' } NOW 24 h
] FETCHRetrouvez la documentation de FETCH.
Vous devriez avoir un graphique du genre :
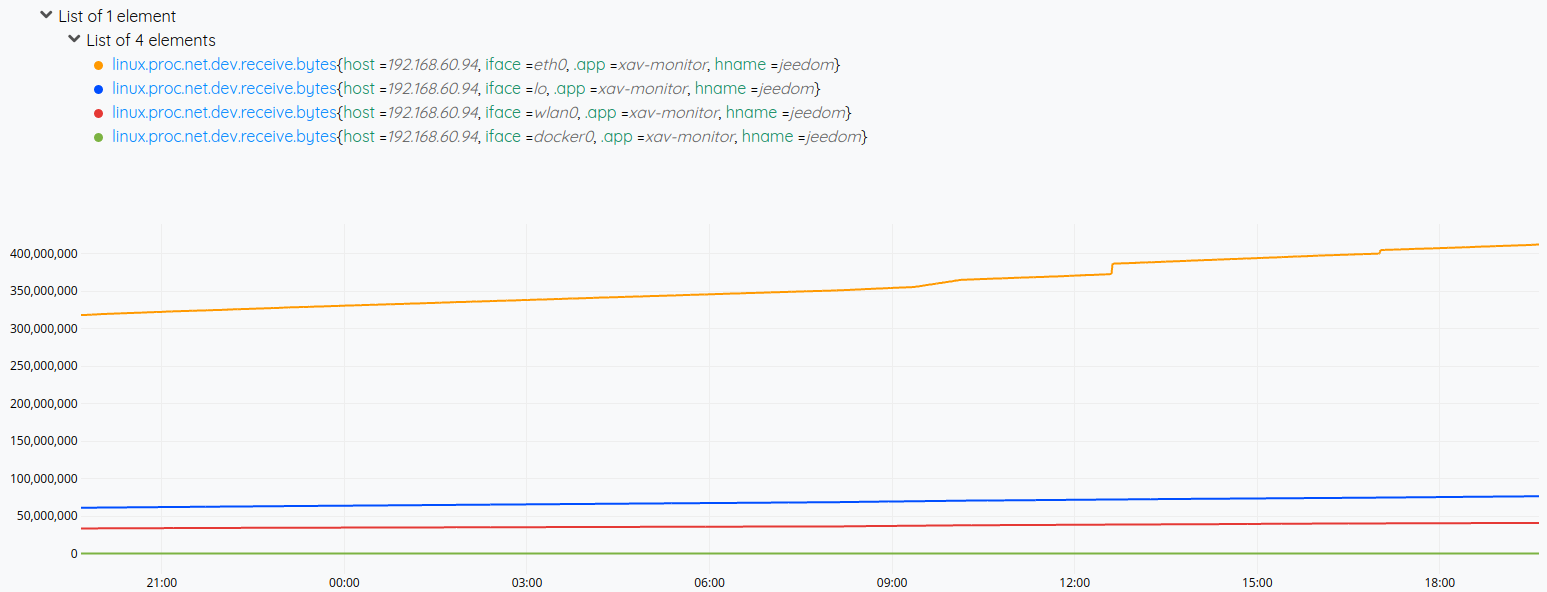
Ok, c’est rigolo, mais allons plus loin. Mettons, je veux 1 mois de données. Ca risque de faire beaucoup. On peut avoir 2 stratégies.
Soit on découpe en tranches avec BUCKETIZE, soit on calcule une courbe representative avec moins de points avec LTTB.
BUCKETIZE
Le principe du bucketize est simple : comment on se partage un saucisson aux noix à plusieurs. Il y a deux façons de le faire, soit on détermine un nombre de tranche (si on est 4, ça fait une grosse tranche chacun), soit on choisis une épaisseur de tranche (des tranches fines donnent l’impression d’en avoir plus). On commence à découper à partir d’un endroit et on remonte dans le passé. Ensuite, on choisis ce que l’on veut faire des noix (quand il y en a, j’y reviendrai) que l’on trouve dans une tranche.
Prenons donc un saucisson :
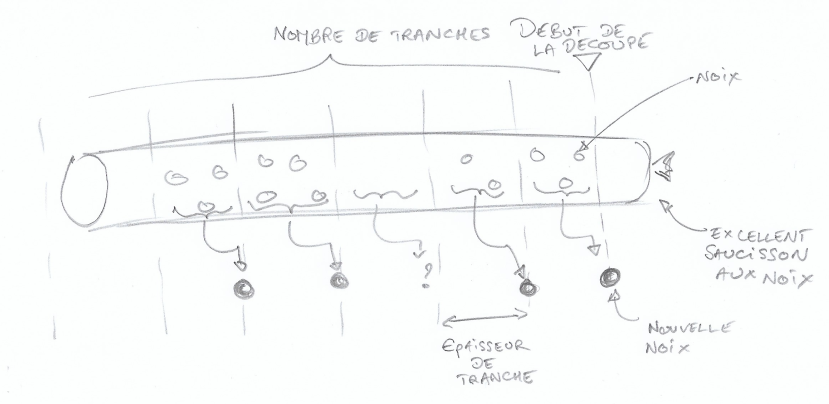
Bref, je commence à découper ma série de valeurs sur 30 jours à un instant T et disons que je choisis une épaisseur de tranche de 1 journée. Je vais avoir 30 tranches de 1 jour de données. Ensuite, j’applique une opération sur les données (mes noix) qui se trouvent dans cette tranche pour calculer une nouvelle donnée (la nouvelle noix) qui aura pour timestamp le début de la tranche.
Par exemple, je commence ma découpe le 30 juin à minuit, ma première tranche à droite contient 3 noix, je décide de calculer la valeur moyenne. Une nouvelle série est créée et son « premier » point sera daté du 30 juin minuit avec comme valeur, la moyenne que j’ai calculé. Ma seconde tranche contient deux noix, même punition, je calcule la moyenne et mon second point sera daté du 29 juin minuit. Troisième tranche, diantre, elle est vide. Ma nouvelle série va contenir un trou (et c’est pas grave, on peut boucher les trous après) daté du 28 juin minuit. Et ainsi de suite.
Ce qui est cool avec le bucketize, c’est qu’il peut prendre un ensemble de séries et produire un nouvel ensemble de séries dont tous les points seront alignés (si l’on choisit une épaisseur de tranche, si on choisi une quantité, ça va dépendre de quand se place le plus vieux point de chaque série). Par exemple, je veux calculer la charge moyenne de mon datacenter, mais mes serveurs ne remontent pas les données au même instant à la micro seconde près. Ce qui est également cool, c’est qu’il y a plein de fonctions sur étagère.
Et pour boucher les trous, il y a FILLPREVIOUS ou FILLNEXT mais encore mieux : FILL
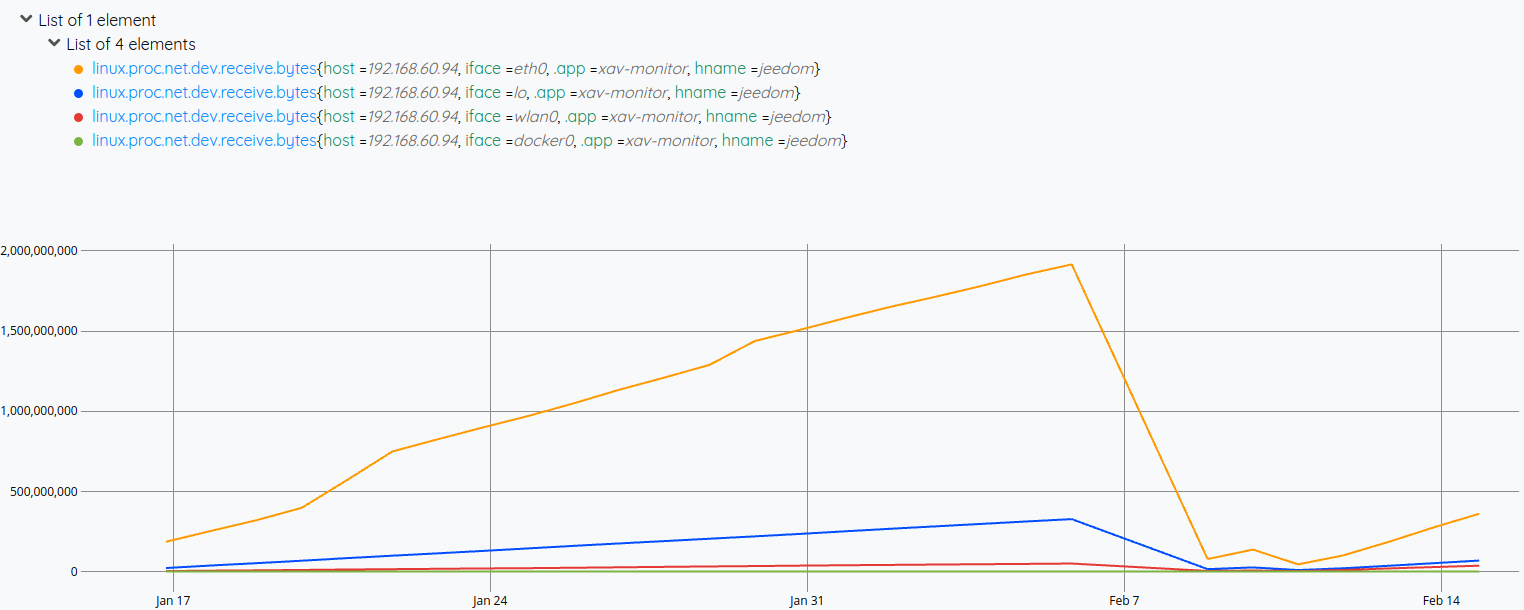
Revenons à notre trafic réseau, ça donnerait un truc du genre :
[
'votre token de lecture'
'linux.proc.net.dev.receive.bytes'
{ 'hname' 'votre serveur' } NOW 30 d
] FETCH 'data' STORE
[ $data bucketizer.mean NOW 1 d 0 ] BUCKETIZERetrouvez la documentation de BUCKETIZE.
Ca nous donne un truc du genre :
LTTB
Cette fonction est puissante et sympa, elle permet de recalculer une courbe représentative en ne spécifiant qu’on nombre de points par courbe (et LTTB accepte une liste de séries en entrée). L’avantage par rapport au bucketize, c’est que l’on ne masque pas des pics ou des valeurs abérantes.
Et pour notre trafic réseau, je veux 1000 points par courbe :
[
'votre token de lecture'
'linux.proc.net.dev.receive.bytes'
{ 'hname' 'votre serveur' } NOW 30 d
] FETCH
1000 LTTB
Des métriques!
Ok, les présentations sont faites, maintenant sortons des métriques de tout ça :
Trafic entrant/sortant
Ah ben oui, tiens, on en parlait. Ben modifions notre script pour y ajouter le trafic sortant avec une expression régulière parce qu’on est des geudins. Filtrons sur eth0 pour le fun et calculons plutôt la variation (le delta entre la valeur n et n-1).
[
'votre token de lecture'
'~linux.proc.net.dev.(receive|transmit).bytes'
{ 'hname' 'votre serveur' 'iface' 'eth0' } NOW 30 d
] FETCH 'data' STORE
[ $data mapper.delta 1 0 0 ] MAP 'data' STORE
[ $data bucketizer.mean $NOW 1 d 0 ] BUCKETIZEAlors, MAP permet de transformer les données d’une série au travers d’une fenêtre glissante (pratique pour calculer une moyenne glissante par exemple) .
RAM/SWAP
C’est pas tellement plus compliqué, on ramène en méga-octets :
[
'votre token de lecture'
'~linux.proc.meminfo.(MemFree|SwapFree)'
{ 'hname' 'votre serveur' } NOW 30 d
] FETCH 'data' STORE
[ $data bucketizer.mean NOW 1 d 0 ] BUCKETIZE 'data' STORE
[ $data 1.0 1024.0 1024.0 * 1024.0 * / mapper.mul 0 0 0 ] MAPAlors oui, pour convertir les octets en méga, c’est un peu casse pied : il faut diviser, donc multiplier par l’inverse. Le mappeur sur étagère de la division n’existe pas, et alors, on a été au collège, non?
1.0 1024.0 1024.0 * 1024.0 * /
se traduit par : 1 / ( 1024 * 1024 * 1024)
Ok, ce n’est pas naturel, mais on a plus de 30 de QI et on a peut être eu une calculette HP dans sa prime jeunesse.
Espace disque utilisé
On monte d’un cran :
[
'votre token de lecture'
'~linux.df.bytes.(capacity|free)'
{ 'hname' 'votre serveur' } NOW 30 d
] FETCH 'data' STORE
// la moyenne quotidienne
[ $data bucketizer.mean NOW 1 d 0 ] BUCKETIZE 'data' STORE
// On extraie capacity pour avoir le total tout montage confondu
[ $data [] 'linux.df.bytes.capacity' filter.byclass ] FILTER 'capacity' STORE
// On calcul donc l'espace disque total cumulé
[ $capacity [] reducer.sum ] REDUCE 'capacity' STORE
// On fait pareil avec l'espace libre
[ $data [] 'linux.df.bytes.free' filter.byclass ] FILTER 'free' STORE
// On calcul donc l'espace disque libre cumulé
[ $free [] reducer.sum ] REDUCE 'free' STORE
// On multiplie par -1 (c'est pour soustraire tout à l'heure)
[ $free -1.0 mapper.mul 0 0 0 ] MAP 'free' STORE
// On se crée une liste de listes de listes que l'on aplatit
[ $capacity $free ] FLATTEN 'list' STORE
// On fait la soustraction, oui c'est comme additionner le négatif
[ $list [] reducer.sum ] REDUCE 'result' STORE
// On converti en méga
[ $result 1.0 1024.0 1024.0 * 1024.0 * / mapper.mul 0 0 0 ] MAPIci on a plusieurs disques, donc on somme le libre (free) et le total (capacity), on multiplie le libre par -1 et on additionne ( – ) le libre et le total (oui on soustraie les 2, 5ème b, madame Grimbert en Math, rappelez vous). Retrouvez la doc de REDUCE.
REDUCE prends une liste de séries, et pour chaque timestamp, prend tous les points correspondant à ce timestamp dans chacune des série et applique une opération à l’ensemble de ces points. A la sortie, on a une série (ou plusieurs si vous faites l’équivalent d’un GROUPBY).
Charge CPU
Là ok, l’algo de calcul n’est pas simple. D’abord, le script :
[
'votre token de lecture'
'~linux.proc.stat.userhz.(user|nice|system|idle|iowait)'
{ 'hname' 'votre serveur' 'cpu' 'cpu' } NOW 30 d
] FETCH 'data' STORE
// Moyenne quotidienne
[ $data bucketizer.mean NOW 0 1 d ] BUCKETIZE 'data' STORE
// On extraie user|nice|system|idle|iowait pour les additionner entre eux
[ $data [] '~linux.proc.stat.userhz.(user|nice|system|idle|iowait)' filter.byclass ] FILTER 'cpuGTS' STORE
// à la sortie du REDUCE, j'ai une liste d'une série, je la récupère
[ $cpuGTS [] reducer.sum ] REDUCE 0 GET 'cpuGTS' STORE
// je récupère l'idle
[ $gts [] 'linux.proc.stat.userhz.idle' filter.byclass ] FILTER 0 GET 'idleGTS' STORE
// J'additionne iowait et idle
[ $gts [] '~linux.proc.stat.userhz.(iowait|idle)' filter.byclass ] FILTER 'iowaitGTS' STORE
[ $iowaitGTS [] reducer.sum ] REDUCE 0 GET 'iowaitGTS' STORE
// Pareil pour system et idle
[ $gts [] '~linux.proc.stat.userhz.(system|idle)' filter.byclass ] FILTER 'systemGTS' STORE
[ $systemGTS [] reducer.sum ] REDUCE 0 GET 'systemGTS' STORE
// Etape 1 on applique une opération custom entre 2 série pour calculer la charge CPU
[ [ $cpuGTS $idleGTS ] [] <%
'd' STORE
$d 7 GET 0 GET 'cpu' STORE
$d 7 GET 1 GET 'idle' STORE
// Le calcule est là
1000.0 $cpu $idle - * $cpu 5 + / 10 / 'v' STORE
[ $d 0 GET NaN NaN NaN $v ]
%> MACROREDUCER ] REDUCE 0 GET 'CPU' RENAME // On renomme la série de résultat
// Etape 2 on calcule l'IO Disk
[ [ $iowaitGTS $idleGTS ] [] <%
'd' STORE
$d 7 GET 0 GET 'cpu' STORE
$d 7 GET 1 GET 'idle' STORE
// Avec ce calcul savant
1000.0 $cpu $idle - * $cpu 5 + / 10 / 'v' STORE
[ $d 0 GET NaN NaN NaN $v ]
%> MACROREDUCER ] REDUCE 0 GET 'Disk IO' RENAME // Et on renomme
// Et enfin on a la charge système
[ [ $systemGTS $idleGTS ] [] <%
'd' STORE
$d 7 GET 0 GET 'cpu' STORE
$d 7 GET 1 GET 'idle' STORE
// Avec ce calcul tout aussi savant
1000.0 $cpu $idle - * $cpu 5 + / 10 / 'v' STORE
[ $d 0 GET NaN NaN NaN $v ]
%> MACROREDUCER ] REDUCE 0 GET 'System' RENAME
// A la sortie, 3 séries pour les charges CPU, Système et IO/DisqueOk, ça pique les yeux. Ici on utilise des MACROREDUCER pour effectuer un calcul custom au sein du reducer. Pour info, on peut faire des opérations custom également pour le bucketize et le map (je dis ça, je ne dis rien).
Je ne vais pas détailler le calcul en lui même, comme dirait Kâ, ayez confianssssssssse.
Toujours est-il qu’on a récupéré un paquet de séries, qu’on les a ventilé en fonction de leur petit nom pour en faire un calcul sur des sous ensembles et forgé de nouvelles séries correspondant à nos KPIs (oui, ça sonne bien hein?) avec.
Pour aller plus loin
Je vous encourage à aller voir warp10.io pour découvrir tout la puissance du langage WarpScript (un peu tordu de prime abord) qui permet d’exprimer en peu de code des algos puissants. Il y a une fonction pour presque tout (oui, pas la division ni la soustraction, mais on a tous notre brevet des collèges alors).
Concernant la division ou la soustraction de 2 séries, il y a plus simple :
serie1 serie2 /
serie1 serie2 -Mais quand on a des listes de séries, il faut faire autrement.
Dans les prochains articles, on va voir comment on peut ajouter de nouveaux métriques (process en cours par exemple) et se faire un dashboard de hipster joli tout plein sans tomber dans le mainstream moutonnier de Grafana (même si c’est possible).


